
- 1章 DB設計
- 2章 論理設計と物理設計
- 3章 論理設計と正規化
- 4章 ER図
- 5章 論理設計とパフォーマンス
- 6章 データベースとパフォーマンス
- 7章 論理設計のバッドノウハウ
- 8章 論理設計のグレーノウハウ
- 9章 一歩進んだ論理設計
1章 DB設計
3層スキーマ
- 外部スキーマ: ビューの世界(ユーザから見たDB)
- 概念スキーマ: テーブルの世界(開発者から見たDB:DBに保持するデータの要素および、データ同士の関係を記述するスキーマ)
- 内部スキーマ: ファイルの世界(DBMSから見たDB:概念スキーマで定義された論理データモデルを具体的にどのようにDBMS内部に格納するかを定義するスキーマ)
概念スキーマが存在している理由は外部/内部スキーマの変更時に、緩衝する層を入れることで変更に強い構成にしている(内部スキーマをいじってデータの格納方式を変えたい場合に、外部スキーマに影響を与えてしまう)
演習問題
- 問題1
- 実行計画やslow queryログを参照して原因となるSQLを見つけ改善を行う
- SQLの実行が遅い原因を調査する cpu / mem / nw / io など
- 単純にクエリがでかい可能性は並列化できないか?を検討する
- 問題2
- スケジュールを確認し、スケジュールの範囲でおさまるかを確認する
- おさまらない場合は顧客と優先度について話し合う
- やるとなった場合は再度要件をヒヤリングして、必要に応じてデータモデルを変更する
- データを用意し、帳票出力するコードを修正する
2章 論理設計と物理設計
概念スキーマを定義する設計のこと
論理設計のステップ
- テーブル定義: 概念スキーマをベースにテーブルにする
- インデックス定義
- ハードウェアのサイジング
- キャパシティとパフォーマンスの観点から
- 性能問題の8割はディスクI/O
- ストレージの冗長構成決定
- RAID 5 / 1+0
- ファイルの物理配置決定
ファイルの物理配置
- データファイル
- インデックスファイル
- システムファイル
- 一時ファイル: SQLのサブクエリを展開したデータやソートデータなど
- ログファイル
バックアップとリカバリ
- バックアップ
- フルバックアップ
- 増分バックアップ
- 差分バックアップ
- リストアとリカバリの違い
- リストア: バックアップディスクからデータファイルを復旧
- リカバリ: トランザクションログからデータを復旧
- ロールフォワード: DBサーバに残ってるトランザクションを適用して復旧
3章 論理設計と正規化
用語
- 主キー: 1テーブルにつき1列
- 業務で重要な役割を果たすことはほぼないけど設計理論上存在するやつ
- 候補キー(candidate key): 主キーとして利用可能なキーが複数存在した場合、それらの候補となるキーのこと
- スーパーキー(super key): 主キーに非キー列を付加した場合のキーの組み合わせのこと
- 外部キー: 二つのテーブル間の列同士で設定する
- カスケード
- 外部参照している値が存在しなくなった場合の動作は自分で規定できる。この動作のことをカスケードという。
- ただそもそも外部キーが設定されている場合は子→親の順序で操作するのが良い
制約
- 参照整合性制約: 外部キーと参照しているテーブルに存在しない値を入力できないようにする
- NOT NULL制約:
- 一意制約: 列に対して一意性を求める(主キーとは異なり何列でも指定可能 )
- CHECK制約: 列に入れる値の範囲を指定する
正規化
DBで保持するデータの冗長性を排除し、一貫性と効率性を保持するためのデータ形式。
- 第1正規形: 1つのセルの中には1つの値しか含まない
- 主キーが各列の値を一意に決定できず原則に反するので、1つのセルには1つの値しかいれられない
- 第2正規形: 部分関数従属を排除する(完全関数従属のみのテーブルを作る)
- 主キーの一部の列に対して従属する列がないようにする
- ex: 会社コード -> 会社名 など
- 第3正規形: 推移的関数従属を解消する
- 社員ID -> 部署コード -> 部署名のような二段階の関数従属のこと
- 第2正規形との違いは、主キー直ではないところ
- ボイスーコッド正規形(3.5): 非キーからキーへの関数従属を解消する
- 1対多になるように正規化をしないと可逆的な分解ができなくなる点に注意 p106
- うまくやっても最終的にアプリ側でバリデーションチェックする必要がある点に注意 p107
- 第4正規形: 多値従属性を解消する
- 主キーだけで構成されるテーブルのことを関連エンティティと呼ぶ
- 関連エンティティを作る場合は関連を1つだけにすることが第4正規形
- 第5正規形: 関連がある場合は関連エンティティを作る
演習
- 問題1
- 第1正規形
- 問題2
- 部分関数従属
- 支社コード->支社名
- 支店コード->支店名
- 商品コード->商品名
- 推移的関数従属
- 商品コード->商品分類コード->分類名
- 部分関数従属
- 問題3
- 支社-支店テーブル(支社コード/支店コード)
- 支店-商品テーブル(支店コード/商品コード)
- 支社-商品テーブル(支社コード商品コード)
- 支社テーブル(コード/名前)
- 支店テーブル(コード/名前)
- 商品テーブル(コード/名前/分類コード)
- 分類テーブル(コード/名前)
- ※やりすぎた第3までで良かったらしい
4章 ER図
- エンティティの数が増えたときに相互の関連を効率的に把握するためにER図が存在する。
- IE表記法とIDEF1Xの書き方がある
- IDEF1Xの方が複雑
- 関連実体
- 多対多の状況の時に、間を埋めるために作られるエンティティのこと
- 例:学生と授業というエンティティがあったときに、間に受講というエンティティを噛ませる
演習
- 問題1
- ER図を書く
- 問題2
- 支店商品
- ※支店と商品は本来多対多であるから
- 問題3
- 本屋と本
- 本管理という関連エンティティを入れ、本屋と本を紐付ける
- テレビと番組
- チャンネル管理という関連エンティティを入れて、テレビと番組を関連付ける
- Amazonのアカウントと購入した商品
- 購入履歴をいれて関連付ける
- 本屋と本
5章 論理設計とパフォーマンス
- 正規化するとjoinが必要になるのでSQLパフォーマンスが悪化する
- 対応方法は非正規化か、SQLに対するチューニング
- 非正規化は最後の戦略
パフォーマンス向上の方法
- テーブルにサマリーデータを追加する
- 結果的に推移的関数従属が発生し第二正規形となる
- 選択条件を別テーブルにも追加する
- テーブルのjoinをすることなく選択検索ができるように同じ内容をテーブルに追加する
- 部分関数従属が生まれるので第一正規形となる
冗長性とパフォーマンスのトレードオフ
非正規形は
- 検索のパフォーマンスを上げるが、更新のパフォーマンスを下げる
- データのリアルタイム性を低下させる
- 後続の工程で設計変更すると手戻りが大きい
- コード ベースの修正と比較して改修コストが大きくなる
- DOA(Data oriented architecture)なので元を変えるのが大変
演習
- 問題1
- 問題2
- SQL1: 商品テーブルに分類名追加 or 商品分類テーブルにサマリー追加
- SQL2:
6章 データベースとパフォーマンス
インデックス
インデックスの利点
- アプリケーションのコードに影響を与えない
- テーブルのデータに影響を与えない
- 性能改善の効果が大きい
B-treeインデックス
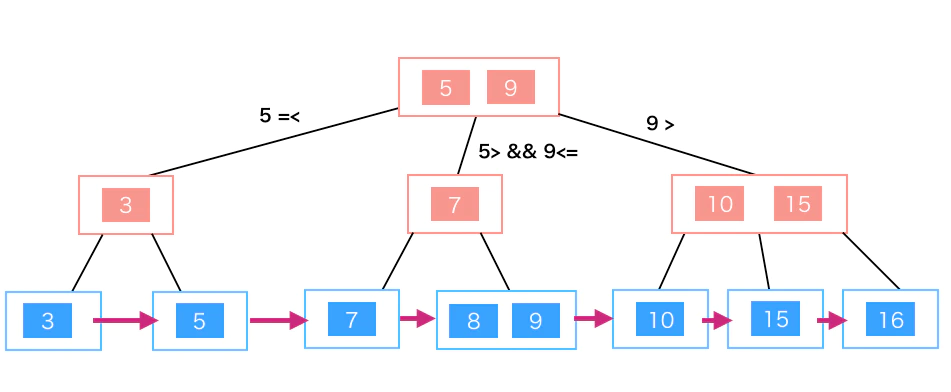
引用元:B-TreeとB+Treeに関して簡単に説明 - Qiita
- 平均点が全体的に高く、実質使われているのはこれ
- 各能力
- 均一性: 各キー値の間で検索速度にばらつきが少ない
- 平衡木: どのリーフもルートからの距離(高さ)が一定の木
- データ増えてくると非平衡木になるが自動修復機能もある
- 持続性: データ量の増加に対してパフォーマンス低下が少ない
- O(logN)
- フルスキャンはO(N)
- 処理汎用性: 検索、挿入、更新、削除のいずれの処理もそこそこはやい
- 非等値性: 不等号つかってもそこそこはやい
- 親ソート性: ソートが必要な処理を高速化できる
- SQLは一切の手続きを記述しないのでORDER BYとかCOUNTなどいくつかの処理を記述したときにのみソートが行われる
- しかしソートはコストが高い演算で、DBMS内で専用のメモリ領域が割り当てられておりその内部に一時的にデータを保持して処理が実施される
- 大量データのソートが必要な場合はメモリに乗り切らないために溢れてしまうことがあるが、その時は一時的にディスクへデータを書き出す。
- これによってI/Oコストが非常に大きくなるのでSQLを書く際は大きいソートを避けるのが良い
- インデックスを使うとこれを解消できる(ソートの役割を有するので)
- 均一性: 各キー値の間で検索速度にばらつきが少ない
- B-Treeインデックスを作るべき場所
- 大規模なテーブル(感覚としては1万レコード以上)
- カーディナリティの高い列
- カーディナリティ: 特定の列の値がどのぐらいの種類の多さを持つかを表す概念
- 性別なら男/女/不明で3、日にちなら365
- 注意点
- 複合列の組み合わせでカーディナリティを考える
- カーディナリティが高くても特定の値に集中する場合は使用を避ける(1~100まであるけど値のほとんどが50の場合)
- SQLでWHERE句の選択条件、または結合条件に使用されている列
- NG例
- インデックス列に演算をしている
WHERE col * 1.1 > 100->col > 100/1.1 - 索引列に対してSQL関数を適用している
WHERE SUBSTR(col, 1, 1) = 'a' - IS NULL述語を使っている
WHERE col IS NULL(DBMSによってはイケることも) - 否定形を用いている
WHERE col <> 100 - ORを用いている
WHERE col = 99 OR col = 100-> INで書くとイケる IN(99,100) - 後方一致、または中間一致のLIKE述語を用いている
- OK:
WHERE col LIKE 'a%' - NG:
WHERE col LIKE '%a' or LIKE '%a%'
- OK:
- 暗黙の型変換を行っている
- colが文字列型の場合
WHERE col = 10->WHERE col = '10'or キャストする
- colが文字列型の場合
- インデックス列に演算をしている
- NG例
- そのほか
- 主キーや一位制約の列には作成不要
- インデックスは更新性能を劣化させる
- 定期的なメンテナンスを行うのが良い
- 構造が崩れている指標値(断片化率/気の高さ)がある
統計情報

引用元:第4回 クエリ評価エンジンと実行計画―“シェフおまかせ”はいつも美味しいのか(1) :DBアタマアカデミー|gihyo.jp … 技術評論社
統計情報とはオプティマイザが最適な実行計画を立案するために必要とするメタデータのことであり、カタログマネージャが管理している。
統計情報はデータが大きく更新されたあとなるべく早く取る必要があるが、テーブルが大きい場合には時間がかかるのでシステムの使用者が少ない夜間に実施することが原則となっている。
一応選択肢として「統計情報をロックする」 やり方もある。これはサービス終了までの道のりが見えており、その時のデータに対して最適な実行計画が生成できる統計情報が準備できているのであれば途中でいじる必要はないというものである。
演習問題
- 問題1
| 名前 | 仕組み | pro | con |
|---|---|---|---|
| ビットマップインデックス | 列の値に対してビットマップ(01000..のようなビットで情報を可視化する)を設定し、検索時に条件で指定されたビットが立っているものだけを抜き出す方式。カーディナリティが低い列に対して有効 | 持続性/非等値性(<>もいける)/ORつかえる | 均一性/処理汎用性/親ソート性 |
| ハッシュインデックス | 列の値に対してハッシュを求め、ハッシュ値を管理する。検索時はハッシュと一致しているか?という観点で情報を抜き出す方式。 | 持続性/均一性/処理汎用性(性能非常に高い) | 非等値性/親ソート性 |
- 問題2
7章 論理設計のバッドノウハウ
テーブル分割
- 水平分割: レコード単位にテーブルを分割する
- 垂直分割: 列ごとにテーブルを分割する
- 水平分割
- 原則使うべきではない
- 分割することに性能以外の論理的な意味合いを持たず、また拡張性に難があることが多く、DOAの原則的にアプリに改修が都度発生する場合がある。パーティションをうまく使って計算量を減らすことで論理的に水平分割されている状況を作るという選択肢がある
- 垂直分割
- 原則使うべきではない
- 分割することに性能以外の論理的な意味合いを持たない
- 集約を使うことで垂直分割を回避する
集約
できることは列の絞り込みとサマリテーブル
- 列の絞り込み
- 既存のテーブルのうちよく参照される列のみをもった新しいテーブル(データマート)を作成する
- データマートと元のテーブルは定期的にデータ同期が必要
- 多くの場合1~数回/日 (ただしここは要件次第)
- データマートを作るための方法としてマテリアライズドビュー機能がある
- サマリテーブル
- 平均や合計などソートを含むことで処理に時間がかかるケースでは、その値を含んだテーブルをはじめから作ることで平均値を求める時に単純なSQLで解決できるようにする
- ただしこちらも同期の問題がある
- 平均や合計などソートを含むことで処理に時間がかかるケースでは、その値を含んだテーブルをはじめから作ることで平均値を求める時に単純なSQLで解決できるようにする
自分で調べたが「ビュー」というのもサマリテーブルと似たことができるようである。というのもビューは複数の表の結合や集約などを事前に行なっておけるテーブルであるためこれを使える。
サマリーテーブルは一度作成すれば計算が不要なので、Viewと比較すると処理が早い。 反対にViewの処理は毎回計算されるので遅いが常に最新のデータを返してくれる。 用途によって上手に使い分ければよい。
引用元 ViewとSummaryテーブルの使い分け – variable.jp [データベース,パフォーマンス,運用]
演習問題
- 問題1
| 名前 | 内容 | pros | cons |
|---|---|---|---|
| レンジパーティション | キー項目の値の範囲で分割(0<x<100とか) | ピンポイントに強い | レンジを変えるたびに作り直す必要あり |
| リストパーティション | キー項目の値を固定値で分割(都道府県で47分割とか) | レンジに強い | 固定値増える/変わる度に作り直す必要あり/パーティション間で偏りが生じやすい |
| ハッシュパーティション | キー項目の値から決められた数のパーティションに自動で均等に分割 | 性能が均等に分散される | 不等式などは使えない |
レンジ、リストを使う場合には値が変動しない(しにくい)ことや、対象のキーが検索条件に使用されること、各キーへのアクセス数がある程度均等である場合に用いるようにする。
- 問題2
- ビュー: 実体を持たない。そのため参照がある度に検索・集計処理(SQL)が走る
- マテリアライズドビュー(マテビュー): 実体はテーブル。そのため、複雑な検索・集計処理でも高速に結果を得ることができる
- ただし常に最新の検索・集計結果を保持しているわけではなく、更新処理(リフレッシュ)が必要になる
- 同様の仕組みは手作業でサマリテーブルを作成することで実現できますが、マテリアライズドビューの場合は、リフレッシュ操作(SQL文は後述)だけでデータを更新できるので、メンテナンスが楽です。 [Tableau]PostgreSQLのマテリアライズドビューを使用する | DevelopersIO
- ビューとマテリアライズド・ビューの違いを理解する
| 名前 | データ鮮度 | パフォーマンス | データを保持するか | データの格納領域 |
|---|---|---|---|---|
| ビュー | 高(リアルタイム) | 低 | しない | - |
| サマリテーブル | 中(タイミング次第) | 高 | 永続 | 任意(通常はデータファイル) |
| マテリアライズドビュー | 中(タイミング次第) | 高 | 永続 | 任意(通常はデータファイル) |
| 一時テーブル | 中(タイミング次第) | 中(物理設計と統計情報に注意) | 一時的 | 一時ファイル |
8章 論理設計のグレーノウハウ
代理キー
設計不備や業務要件、そのほか様々な理由によりテーブルにて主キーがこれ以上用意できないとなった時に利用するためだけの主キーのことを代理キーと呼ぶ。(反対にきちんとした理由で設定される主キーのことを自然キーと呼ぶ)
代理キーは論理的には意味のあるものではないので使わないに越したことはないため、本来の主キーに加えてタイムスタンプやインターバルを用いた方法にて解決を目指す方が良い。
ビュー
- クエリの缶詰
- 保存が聞く上にあければ常に新鮮なデータが取れる
- 物理的にはSQL文が書かれたファイルに過ぎない
- ユーザ -> ビュー -> テーブル
データクレンジング
これまでの業務で使われてきたデータをDBに登録できる状態にすることが必要になり、このことをデータクレンジングという。具体的にはデータのフォーマットが適切かを調査して、必要ならデータそのものの変更やフォーマット変換を行う。
- 一意キーの設定
- 名寄せ(データ形式を整える)
演習問題
- 問題1
- 問1
- テーブルの制約でできるものをアプリ側で実装することは車輪の再発明になるだけではなく、複数のアプリにてDBの処理が行われる場合に同じ機能を実装+テストする必要があり工数やセキュリティのリスクが発生するため可能な限り避けるべきである
- 問2
- トリガーとは「特定のテーブルに対する操作(挿入・更新・削除)を契機として、あらかじめ定義された処理を自動的に実行する機能」のこと
- どこまでの処理をDBに任せるか?によると思うのだが、アプリ側でそれを契機に何かをする必要があったり、その変更状況を定期的にポーリングする必要がある場合はアプリ側に寄せた方がいいのではないか?と思っている
- DBMSを変えた時や、スケーラブルな仕組みを導入した際に同じことができるのか?という観点でDBMS側は不向きなのでは?という印象を持っている(あくまで印象)
- こうあるべきといういわばバリデーションに関するところはDBの機能でよいか、動作に関するところはアプリに任せるのが良いかなあと漠然と思っている
- 問1
- 問題2
- 一時テーブル
- MySQLにおいては同一セッション上でのみ有効なテーブルを作成し、セッションが閉じた時に自動で削除されるテーブルのことを指す。
- 利用の是非について
- 一時的なデータの保管場所として利用できるのでそういう用途であれば使うべき
- 一時テーブル
9章 一歩進んだ論理設計
RDBMSは万能ではない。例えば木構造(組織図)を管理する場合にはどのようにその構造を表現するのか?を考える必要がある。
RDBMSでは以下のやり方が存在するが一長一短である。
- 隣接リストモデル
- 入れ子集合モデル
- 入れ子区間モデル
- 経路列挙モデル