
はじめに&注意
公式サイトを眺めて理解した内容をまとめます。
私自身は The Graph を触ったことがなく、ドキュメントを斜め読みしただけなのでこの記事は明らかな誤りや解釈が違っている可能性があります。
必ず公式サイトをチェックするようにしてください。
対象読者
The Graph を理解したいITエンジニア
ブロックチェーンの課題とThe Graph が解決すること
背景
最近のブロックチェーン上ではスマートコントラクトと呼ばれるアプリを動かせます。様々なユーザやDAppsはスマートコントラクトに対してトランザクションを発行して、データを永続化します。
例えば昔流行った「たまごっち」のスマートコントラクトがあるとします。このスマートコントラクトでは餌を上げて、うんちを処理して育てる行為の1つ1つがオンチェーンに登録されるとします。
このとき「ブロックチェーン全体に何体のたまごっちがいるのか?」を調べたい場合はどうすればよいでしょうか?大抵の場合はスマートコントラクトに総数を調べるGetterメソッドがあると思うのでそれを叩けばよいでしょう。
では「いままで30回以上うんちをしたたまごっちの一覧」を知りたい場合はどうすればよいでしょうか?スマートコントラクト側にその機能があれば、同じようにGetterメソッドを実行すればよいですが、そんな限定的なものはきっとありませんよね。他にも複雑な条件でデータを検索したいかもしれません。
もしかしたら「たまごっちDApps」を運営する会社がクエリ用のAPIを公開していればできるかもしれません。
こんな感じ↓
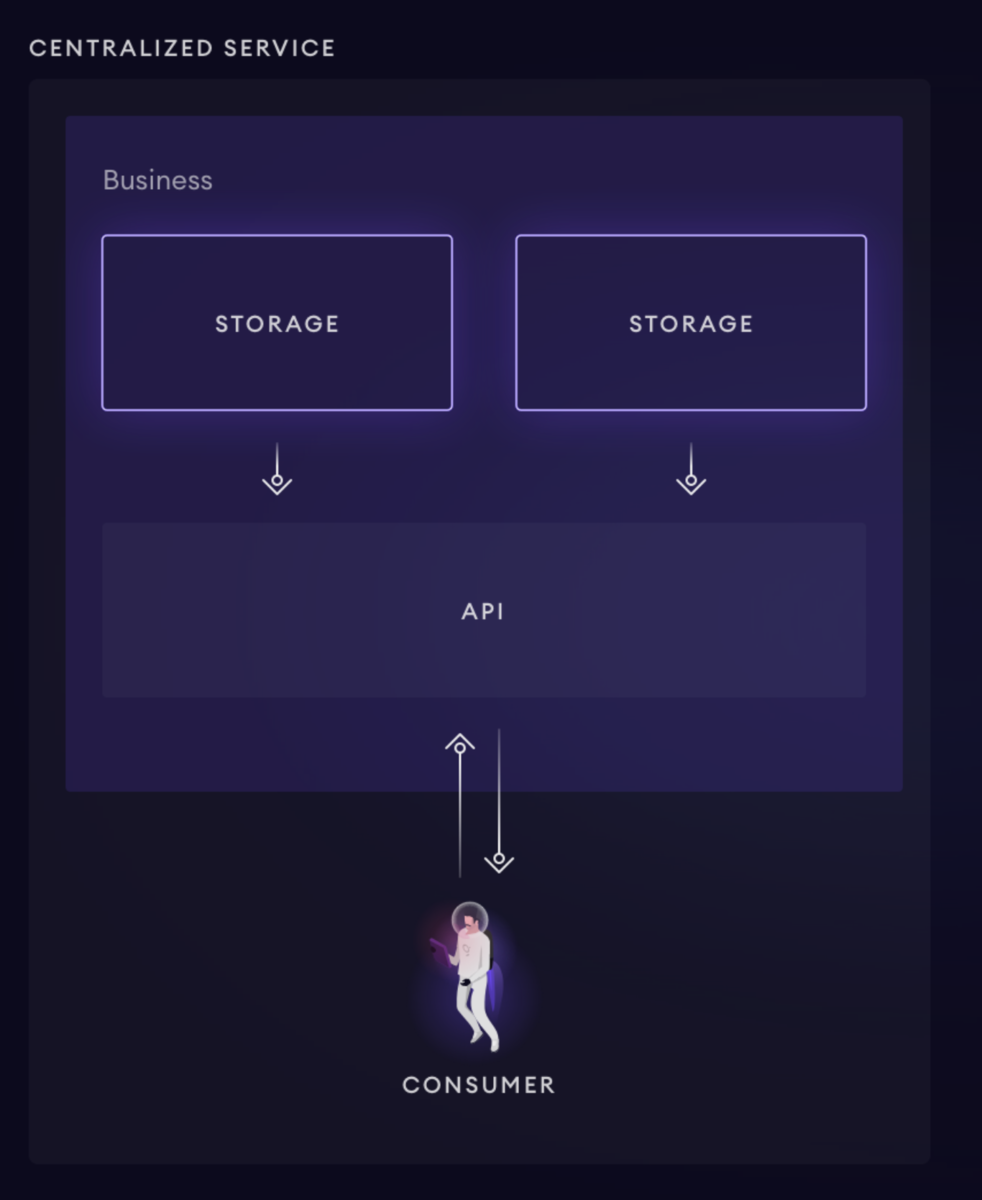
ただこれって非常に中央集権的ですよね。データはオンチェーンで分散化されているのに、検索用のエンドポイントは集権的です。
The Graph が解決すること
The Graph は非中央集権的なクエリを実行するためのエコシステムです。
The Graphを使うとクエリを実行したい人は Graph Node に対して GraphQL を発行するだけで、任意のデータをブロックチェーン上から取得することが出来ます。
これによりオンチェーン上のデータを好きな条件で検索できるようになります(以下は一例です)。
- いままで30回以上うんちをしたたまごっちの一覧
- これまで生まれたたまごっちの数
- 名前が「たまご.*」を満たすたまごっちの数
The Graph の概念
- システムのアーキテクチャ
- 非中央集権的なシステムを維持するインセンティブ設計
の順に紹介します。
The Graph のシステムアーキテクチャ
The Graph はブロックチェーン上のデータをクエリできるようにするための仕組みです。そのため大きく分けて2つの機能があります。
- データを貯める仕組み
- エンドポイントを用意して、クエリに対してレスポンスを行う機能
ここではこの2つについて紹介します。
データを貯める仕組み
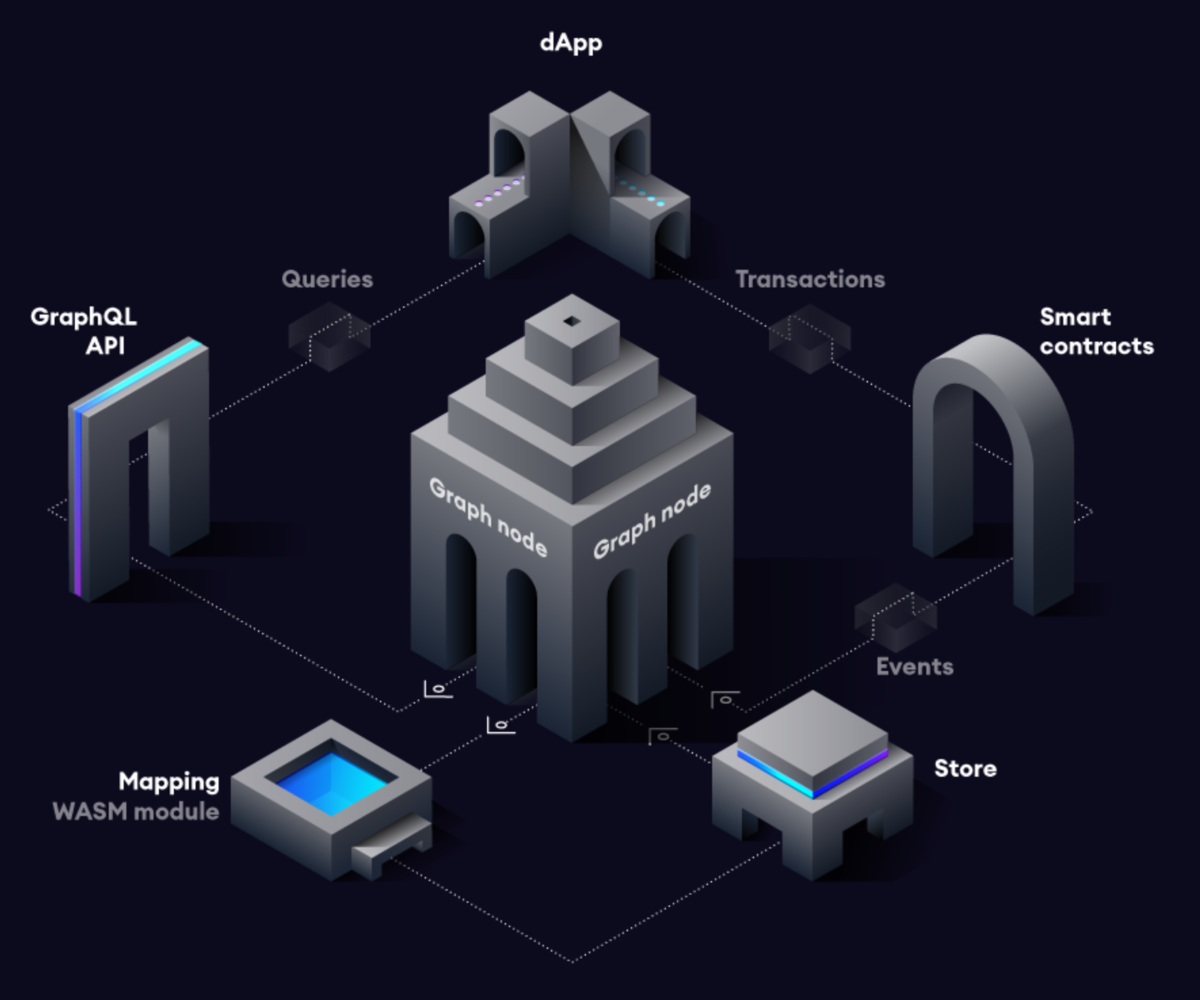 Introduction - The Graph Docs より引用
Introduction - The Graph Docs より引用
上記の図の右側がデータの流れです。
- DApps がスマートコントラクトを通じて、ブロックチェーン(Ethereumなど)にデータを書き込む
- スマートコントラクトは書き込みイベントを発行する
- これはThe Graph 関係ない一般的なスマートコントラクトの動作です
- (2とは関係ない時間軸で) Graph Node (The Graph用のアプリが動いているサーバ) はサブグラフマニフェストの設定に従って、ブロックチェーン上の新しいブロックとデータをチェックしている
- Graph Nodeがサブグラフマニフェストに定義された条件に合致するイベントを見つけたら、データをデータストアに格納する
サブグラフ(SubGraph) とは
あまりうまく説明できないので公式からコピーします。
A subgraph defines which data The Graph will index from Ethereum, and how it will store it.
サブグラフは、グラフがイーサリアムからインデックスを作成するデータと、それを保存する方法を定義します
自分の解釈では「どのブロックチェーンから、何のデータを引っ張ってきて、どうクエリさせるか定義したもの」という The Graph の中で使うワードというイメージです。
サブグラフは以下の3つのファイルでその振る舞いを定義されます。
| ファイル名 | 内容 |
|---|---|
subgraph.yaml |
サブグラフの定義ファイル |
schema.graphql |
GraphQLスキーマ(サブグラフに保存するデータとクエリ方法の定義) |
AssemblyScript Mappings |
ブロックチェーンの event をGraphQLスキーマに対応したデータに変換する AssemblyScript コード |
実際に公式サイトのサンプルを見ていきましょう。
サブグラフの定義ファイルである subgraph.yaml は
- どのブロックチェーンの
- どの event をチェックするか
- どのように mapping するか(mapping に使うスクリプトを指定)
を定義しています
specVersion: 0.0.4 description: Gravatar for Ethereum repository: https://github.com/graphprotocol/example-subgraph schema: file: ./schema.graphql dataSources: - kind: ethereum/contract name: Gravity network: mainnet source: address: '0x2E645469f354BB4F5c8a05B3b30A929361cf77eC' abi: Gravity startBlock: 6175244 mapping: kind: ethereum/events apiVersion: 0.0.6 language: wasm/assemblyscript entities: - Gravatar abis: - name: Gravity file: ./abis/Gravity.json eventHandlers: - event: NewGravatar(uint256,address,string,string) handler: handleNewGravatar - event: UpdatedGravatar(uint256,address,string,string) handler: handleUpdatedGravatar callHandlers: - function: createGravatar(string,string) handler: handleCreateGravatar blockHandlers: - function: handleBlock - function: handleBlockWithCall filter: kind: call file: ./src/mapping.ts
GraphQL スキーマ( schema.graphql)はこんな感じのようです。
type Gravatar @entity { id: ID! owner: Bytes displayName: String imageUrl: String accepted: Boolean }
event で取得したデータを変換するための AssemblyScript です。
import { NewGravatar, UpdatedGravatar } from '../generated/Gravity/Gravity' import { Gravatar } from '../generated/schema' export function handleNewGravatar(event: NewGravatar): void { let gravatar = new Gravatar(event.params.id.toHex()) gravatar.owner = event.params.owner gravatar.displayName = event.params.displayName gravatar.imageUrl = event.params.imageUrl gravatar.save() } export function handleUpdatedGravatar(event: UpdatedGravatar): void { let id = event.params.id.toHex() let gravatar = Gravatar.load(id) if (gravatar == null) { gravatar = new Gravatar(id) } gravatar.owner = event.params.owner gravatar.displayName = event.params.displayName gravatar.imageUrl = event.params.imageUrl gravatar.save() }
具体的な中身を知らなくてもなんとなく眺めると「あ〜こういう感じか〜」とわかるぐらいのコードでした。ちなみに Graph Node の実装を見ると裏側には PostgreSQL がいたので、データはRDBMS に保存されているようです。
クエリ関連の仕組み
Introduction - The Graph Docs より引用
上記の図の左側がデータの流れです。
- DAppsが Graph Node に対してクエリ(GraphQL)を発行する
- Graph Node が GraphQL endpoint を持っている
- Graph Node はデータストアからデータを取り出し返却する
これで The Graph のベースとなるシステムの話は完了です。
The Graph のインセンティブ設計
登場人物
The Graph を非中央集権的にする登場人物とその利害関係を紹介します。
- 検索したい人(Consumer)
- 検索結果を保存する人(Indexer)
- こんな検索結果を保存して!と提案する人(Curator)
他にもいくつか役割があるが省略!!
検索したい人(Consumer)

イメージとしては「ブロックチェーンに対していい感じでクエリを叩きたいな〜」 って思ってるエンドユーザやアプリケーションのことを指します。
具体的なフローは以下の通り。
- どのIndexer がデータを持ってるか The Graph に問い合わせ
- Consumer はパフォーマンス・価格・データ鮮度・セキュリティを考慮して Indexer を選択
- Consumer は「xx円で??っていう条件のデータほしいな〜」と Indexer に投げます
- 条件がOKの場合、Indexer はクエリ結果と応答が正しいことの証明書を返却します
TODO: ※Attenstation が返ってくると Conditional Micropayment のロックが外れるっていう意味がわかっていない
クエリを叩く際には Indexer に仮想通貨で支払いを行う必要があります。この時に使われる通貨がGRTです。
公式サイト
検索結果を保存する人(Indexer)

Indexer のモチベーションは金稼ぎです。Graph Node を立ててクエリをさばくことで報酬を得ます。
- どのようなデータを保持するのか?
- どのぐらいの頻度で更新するのか?
- どのような価格でクエリを許可するのか?
といったところで他の Graph Node を管理する Indexer と差別化を図り報酬を最大化します。
Indexer は Graph Node を公開する際に一定の GRT を預ける必要があるので、悪意を持ったクエリを返却した場合は GRT が没収されます。他にも新しいサブグラフに対してインデックスを生成した場合の報酬もあるようですが、説明を省略します。詳細は公式をご覧ください。
ちなみに理解のためにこんな Node を建てるんだよという情報を貼っておきます。

公式サイト
こんな検索結果を保存して!と提案する人(Curator)

Curator はGRTを使って Indexer に「このデータ価値あるから保存してよ!」と教えて報酬をゲットする人です。主に開発者が Curator になります。他にはこんなのあったら便利だろうな〜と思ったエンドユーザなどもあります。
Indexer はどのデータを保持しておけばよいのかわかりません(より儲かるのかわかりません)。そこで Curator は質の高いサブグラフを Indexer に通知します(これを Signal というようです)。
このサブグラフを indexer が選択して、自分が運営する Graph Node 上でデータを保持します。この Node に対して Consumer からのクエリが発生した場合には Indexer に報酬がいきます。
またこのとき Graph Network から Curatorへ「通知したサブクエリに対するクエリ料金の一部」が報酬として配布されます。
Curator はサブグラフを Indexer に通知する際に、GRTを預けてサブグラフの株式を取得します(この株式は Graph Curation Shares (GCS) と呼ばれる ERC20 トークンです)。
Curator はサブグラフに対するGCSの持ち分に応じてクエリ報酬をゲットできることに加えて、そもそも GCS 取得時にGRT を預けているので Curator はよりよいサブグラフを通知するインセンティブがあります。
※嘘のサブグラフや、儲からないサブグラフを教えると自分が損をすることになる
公式サイト
まとめ
The Graph のやっていることをまとめると 「アプリからGraphQLエンドポイント経由で PostgreSQL にアクセスしてるだけ」 です。
ただし、この Web2 ぽい通信を非中央集権的にするためにいろんな役割や報酬を用意したりしているという感じのようです。