
はじめに
世の中にはすごいエンジニアや、よりよい物を作ろうと工夫しているエンジニアがたくさんいます。しかもその工夫や苦労をネットに公開してくれていることさえあります。
本になっているわけではないので体系的に学ぶことはできないのですが、そこで考えた工夫やエッセンス、調査内容は必ず誰かの糧になると思います。この記事では私が「読む価値がある!」と思った記事を引用しながら、自分の考えを追加して理解を深めていこうというものです。
今回紹介する記事
素晴らしい記事をありがとうございます!
要約
- モノタロウというECサイトにてレイテンシ悪化、バックエンドAPIのタイムアウトが発生した。
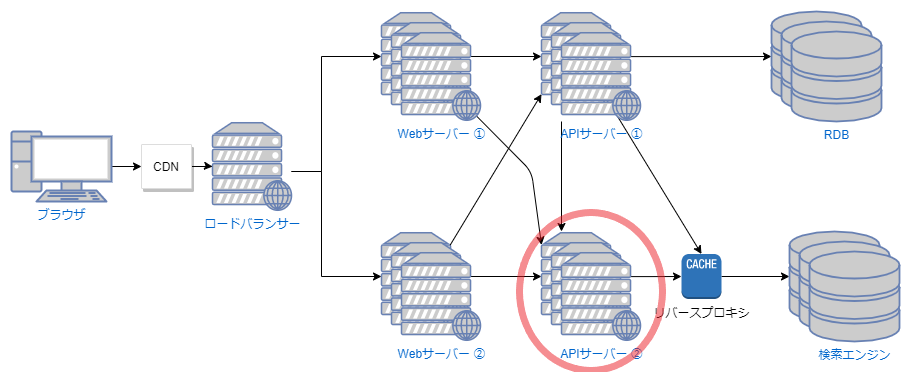
- トラフィック増加に伴うリソース不足の仮説を立てた -> バックエンドAPIをスケールアウトして解決
- 翌週も同じエラーが発生、より深堀をすると「検索エンジンの処理の遅延」が被疑に
- 検索エンジンの増強 -> 解決せず

- 検索エンジンの増強 -> 解決せず
- レスポンスタイムの遅いリクエストの調査をする
- APIサーバのログでは長時間かかっているが、リバースプロキシと検索エンジンのログでは短時間で終わっていた(APIサーバ -> リバースプロキシ -> 検索エンジン という通信フロー)

- リバースプロキシ -> APIサーバの戻りの通信が遅いことに着目
- APIサーバのタイムアウトエラーのトレースを追うとTCPレイヤでのタイムアウトが発生していた
- リバースプロキシの
netstat出力を確認すると、タイムアウト時はSYNパケットがあふれていた- 加えてEC2インスタンスのENIにおいて、接続カウント許容量のクォータの超過(conntrack_allowance_exceeded)も発生していた
- 対策、根本原因解決
- TCPの接続溢れの対策としてリバースプロキシのスケールアウト及びENIのクオータを上げるためにインスタンスタイプの変更も実施した
- Datadogにてネットワーク監視するように追加した
考えたこと/学んだこと
- 各アプリケーションでのログを比較してどこに異常(詰まり)があるのかをチェックする
netstat -sを利用したネットワークレイヤでの通信の状態の確認ができる- 各用語について
- conntrack_allowance_exceeded について
- AWS ENAドライバーで取得できるメトリクス(
ethtool -S eth0 | grep conntrackなどで確認可能) / cloudwatch metricsで取得もできる - 対象のENIにて、コネクションのトラッキング(conntrack)が上限値を超えた場合は、帯域やPPSに余裕があったとしても新しい接続を確立に失敗する
- iptables以外にもconntrackってあったのか
- このトラッキング数を超えたことによってドロップされたパケットの数を意味する
- AWS ENAドライバーで取得できるメトリクス(
- system.net.tcp.retrans_segsについて
- Datadog のメトリクス
- 再送されたTCPのセグメント数を意味する(セグメントとはTCPにおけるデータの送信単位/パケットのようなもの)
- リバースプロキシサーバでこの値が増加していることから、なにがしかの原因でTCPの再送処理が行われていることがわかる
- 今回はconntrackが問題だったが、ENIの帯域やPPS上限に引っかかって上昇する場合があるのでこのメトリクスだけでconntrack要因であることは決定できない。
- conntrack_allowance_exceeded について