GCP Cloud Monitoringを利用する際に前提としてわかっておくべき内容を、個人の備忘として残しておきます。適宜追加していくため不完全な内容になっていますがご了承ください。
メトリクスの種類
| 名前 | 意味 | 例 |
|---|---|---|
| GAUGE | 瞬間的な値 | ある瞬間のCPUの使用率 |
| DELTA | 前回の結果からの差分 | 前回取得したAPIリクエスト数からの増分 |
| CUMULATIVE | 時間とともに累積する値 | サーバの起動時間 |
それぞれのメトリクスは使用できる型が決まっているので、これに準拠して設定を行う必要があります。
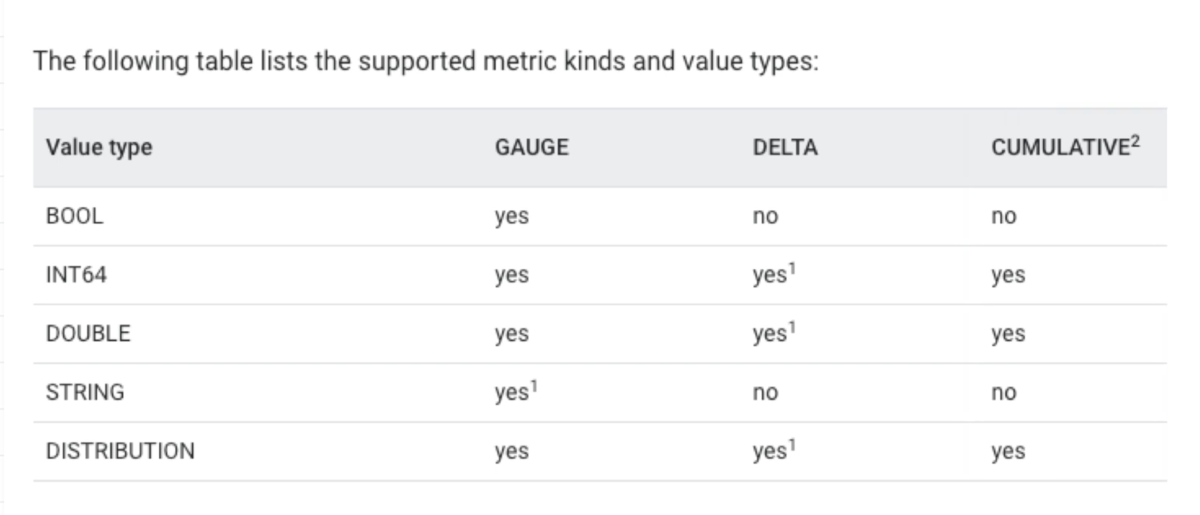
きちんと把握すれば、累積値や前回との差分であるDELTAやCUMULATIVEではBOOLやSTRINGが使えないのは当たり前ですね…。
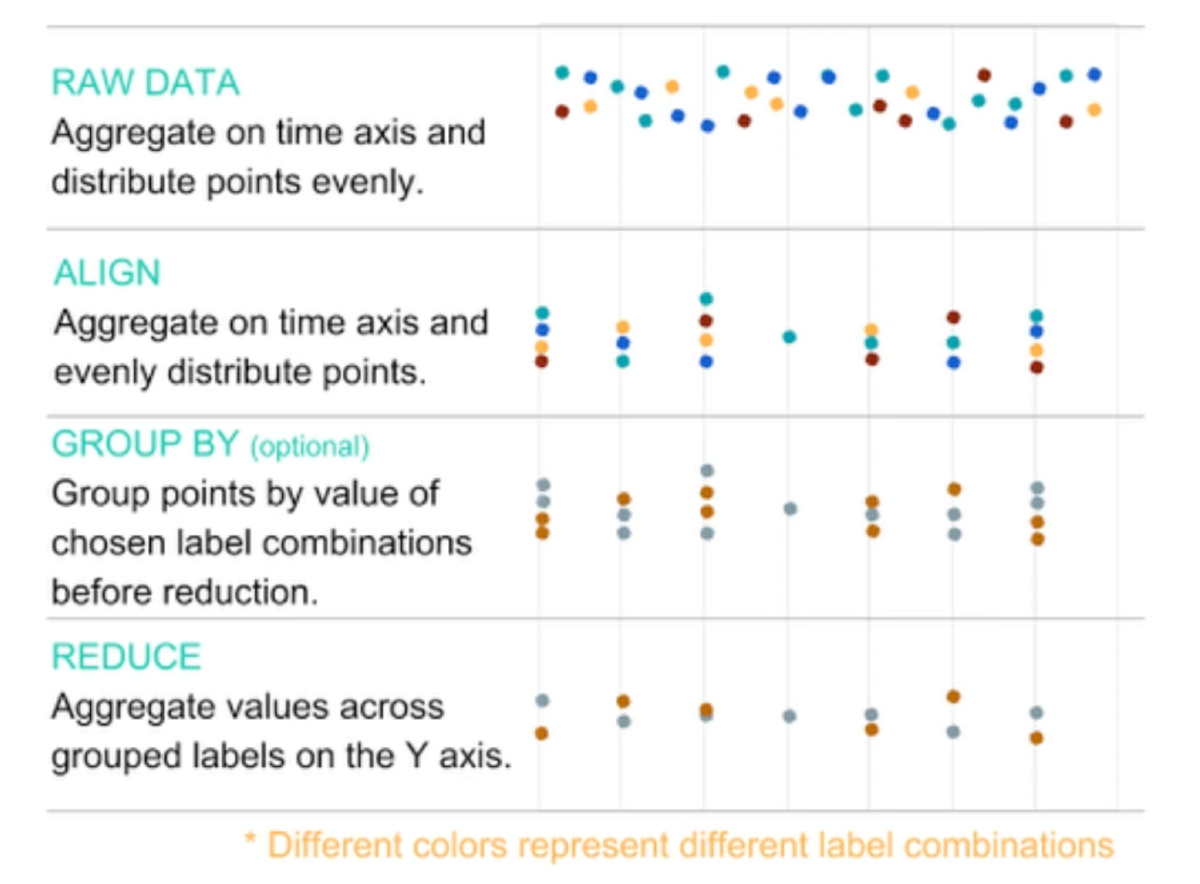
データの整形
生のデータ(=rawデータ)取得するタイミングや、メトリクス収集サーバに飛んでくる時間、飛ばす回数もバラバラのためそのままグラフに表示することができない。
そこで、いかに紹介する手法を用いてデータ数を整えて&減らしてグラフ化する。
| 名前 | 意味 | 例 |
|---|---|---|
| ALIGN | 取得したデータを特定の期間内でまとめて1つにする(X軸) | 5秒に1回取得しているCPU使用率を1分ごとにまとめてデータ数を減らす。このときのまとめ方にはMAX、MIN、AVERAGE、SUM等がある |
| REDUCE | データに付与されたラベル情報を用いて、メトリクスを集約する(Y軸) | 複数のリージョンのストレージのレイテンシーを取得している場合に、リージョンラベルを用いてデータをまとめて、MAX、MIN、AVERAGE、SUM等を用いてデータ数を減らす |
実際にポリシーを読み解く
例1 CPU使用率
{ "displayName": "Very high CPU usage", "combiner": "OR", "conditions": [ { "displayName": "CPU usage is extremely high", "conditionThreshold": { "aggregations": [ { "alignmentPeriod": "60s", "perSeriesAligner": "ALIGN_MAX", "groupByFields": [ "project", "resource.label.zone" ], "crossSeriesReducer": "REDUCE_MEAN", } ], "duration": "900s", "comparison": "COMPARISON_GT", "filter": "metric.type=\"compute.googleapis.com/instance/cpu/utilization\" AND resource.type=\"gce_instance\"", "thresholdValue": 0.9, "trigger": { "count": 1 } } } ], }
わかりやすいように順番は前後しますが以下のような意味です。
alignmentPeriod: 60秒間に取得したデータを利用するperSeriesAligner:alignmentPeriod間で取得したデータをまとめる方法を規定(今回は60秒間の最大値)groupByFields: 各VMのメトリクスをゾーン / プロジェクトでグループ化crossSeriesReducer: ゾーンごとのVMのCPU使用率をREDUCE_MEAN(中央値)を取って1つにするduration: 900秒(15分) ごとにこの監視を行うcomparison:thresholdValueを超えたら(Greater than)filter: GCEのCPU使用率thresholdValue: VMのCPU使用率のしきい値trigger.count: アラートを飛ばすまでにしきい値を超えた回数(仮に2だったら連続2回しきい値を超えない限りアラートが飛ばない)、今回は1なのでチェックに引っかかったら常に飛ばす
まとめると各ゾーンごとのVMの平均CPU使用率(60秒間)の平均が90%を一度でも超えたらアラートを飛ばすチェックを15分に1回行っています。
Terraformで設定できることをまとめる
resource "google_monitoring_alert_policy" "alert_policy" { display_name = "My Alert Policy" combiner = "OR" conditions { display_name = "test condition" condition_threshold { filter = "metric.type=\"compute.googleapis.com/instance/disk/write_bytes_count\" AND resource.type=\"gce_instance\"" duration = "60s" comparison = "COMPARISON_GT" aggregations { alignment_period = "60s" per_series_aligner = "ALIGN_RATE" } } } user_labels = { foo = "bar" } }
| 設定名 | 設定 | 意味 |
|---|---|---|
| combiner | AND / OR / AND_WITH_MATCHING_RESOURCE |
conditionsで設定する条件が複数の場合にアラートを発生させる条件。conditionsに複数条件が存在する場合にANDの場合は両方を満たすし、ORの場合は片方が満たされればアラート発生条件を満たす。ややこしいのは ANDとAND_WITH_MATCHING_RESOURCEの違いで、あるアラートに複数のGCEが引っかかった場合にCPUとメモリの条件をつけたときに、ANDの場合はVM1のCPUとVM2のメモリがしきい値を超えるとアラートが飛んでしまう。AND_WITH_MATCHING_RESOURCEはより厳密にVM1のCPUとメモリが超えない限りアラートが飛ばないAlerting behavior | Cloud Monitoring | Google Cloud |