この記事ではkubernetesで障害が発生した時の挙動と接続断時間をまとめます。

結論
| 状況 | Pod数=1 | Pod数=2 |
|---|---|---|
| Drain(ノードをクラスタから除外) | 実施不可 | 瞬断 |
| Pod削除(1つ) | 瞬断 | 瞬断 |
| Dockerプロセス停止 | 100% 断(復旧まで) | 50% 断(–pod-eviction-timeoutの間) |
| ノード停止/kubelet停止 | 100% 断(復旧まで) | 50% 断(–pod-eviction-timeoutの間) |
※Pod数が増えた場合は(ノード数=Pod数ならば) 1 / ノード数 で算出できます
1 Podで起動している時
このような構成を考えてみましょう。
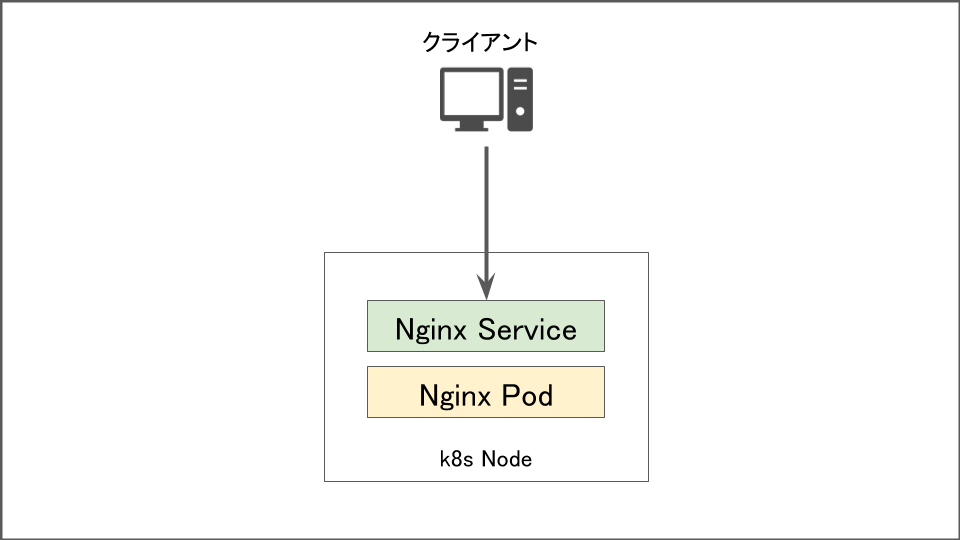
Podが削除された場合
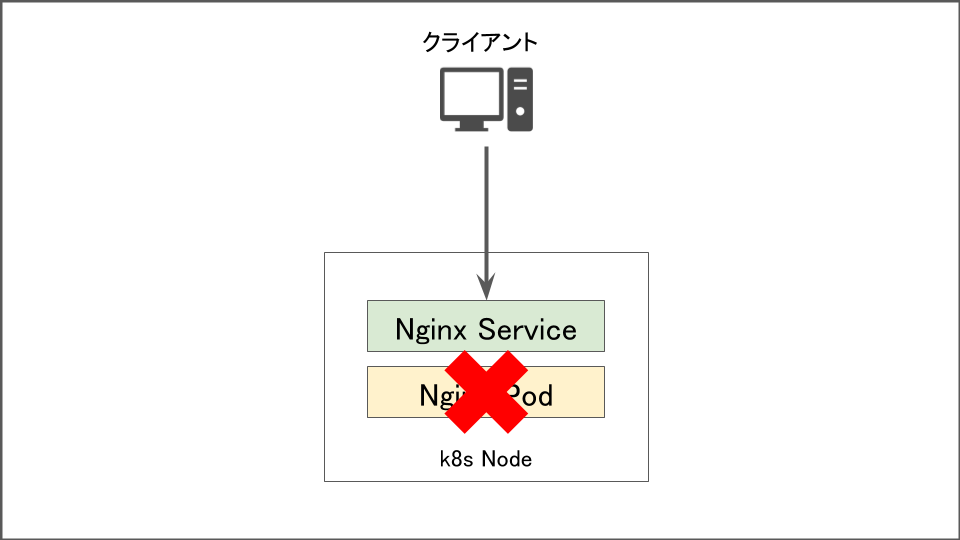
この場合はkubernetesの宣言的な機構が働き2~3秒で復旧します。
Dockerプロセスが停止した時
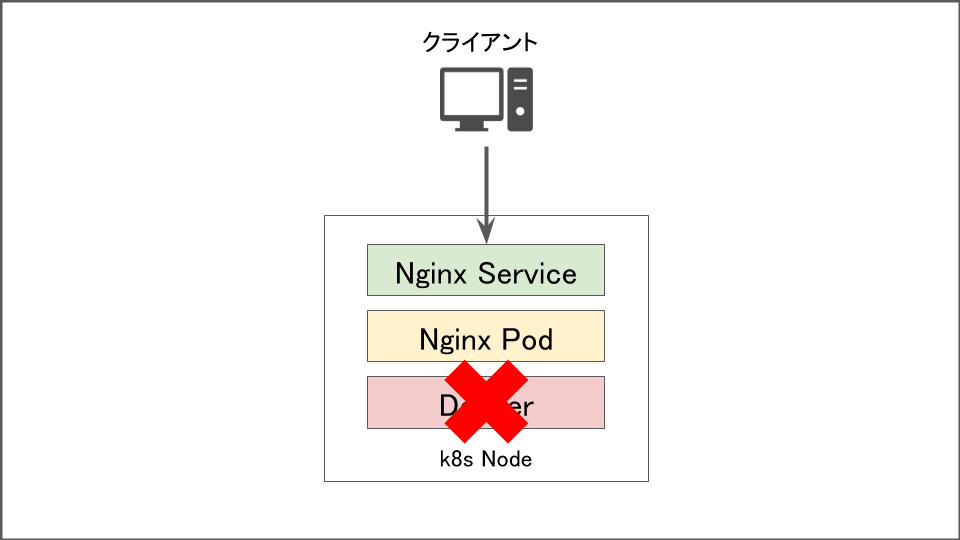
コンテナやpodを稼働させるDockerプロセスが停止したときは通信が全断します。Dockerプロセスを起動し直すまでは通信不可です。
nodeが停止&kubeletプロセスが停止した時
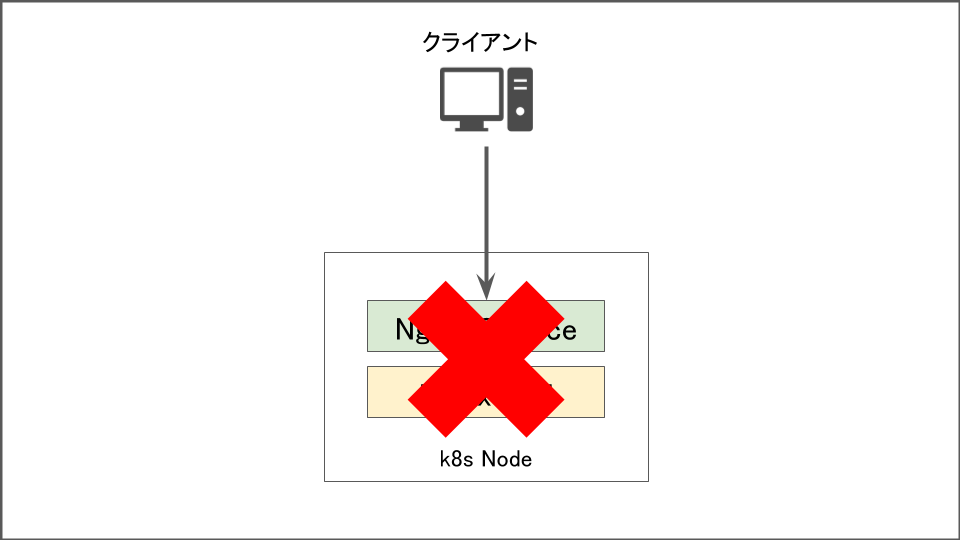
MasterとNode間はkubeletプロセスが通信を行なっていますので、kubeletプロセスを停止したときはノードが停止している時と同じ挙動となります。
この場合はノードが復旧しPodが再起動するまで通信が全断となります。
複数Podで起動している時
このような構成を考えてみましょう。
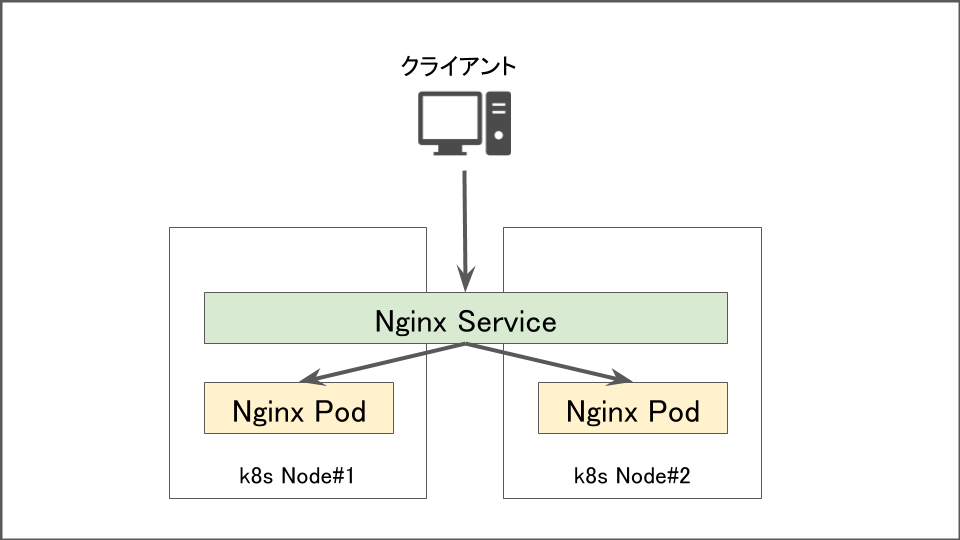
Nodeをクラスタから排除した場合
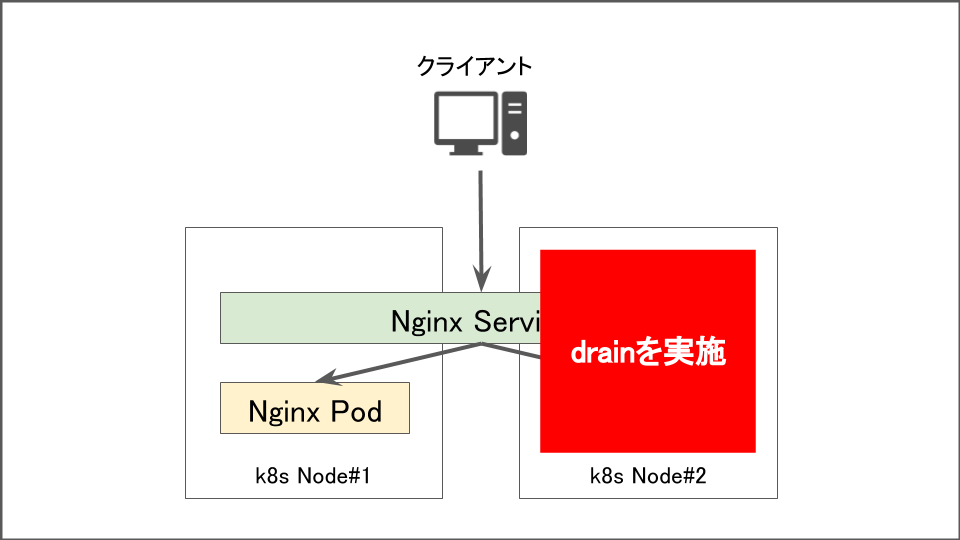
kubectl drainコマンドを使って影響を受けないように排除した場合は該当のノード上で稼働しているPodが別のノードに移動します。アプリや通信量にもよりますが、即時に実行されるため瞬断以外は発生しません。
podが削除された場合
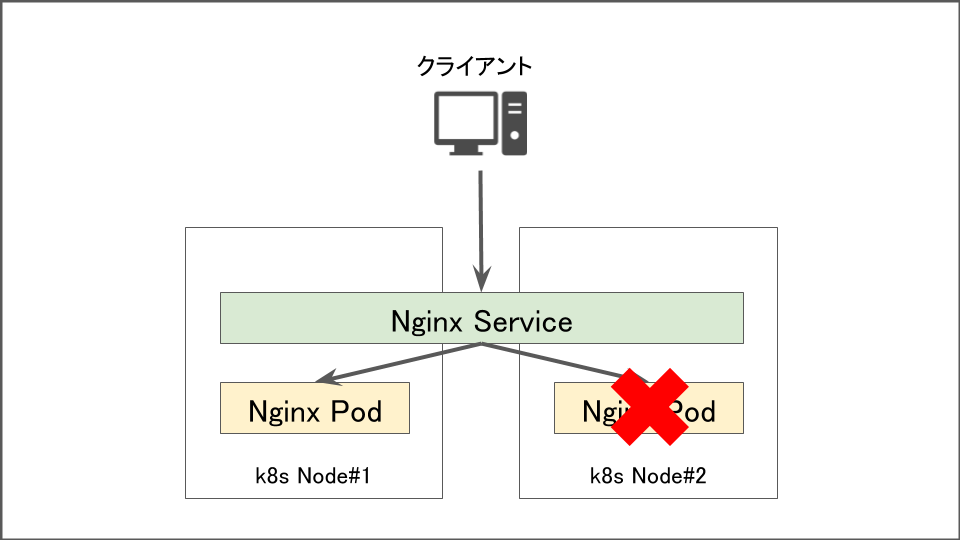
この場合はkubernetesの宣言的な機構が働き2~3秒でpodが復旧します。アプリや通信量にもよりますが、即時に実行されるため瞬断以外は発生しません。
Dockerプロセスが停止した時
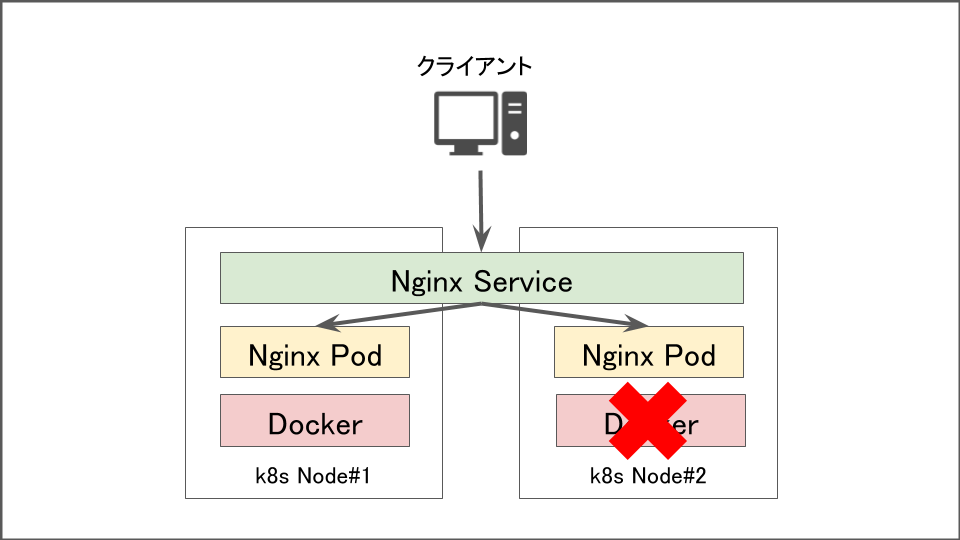
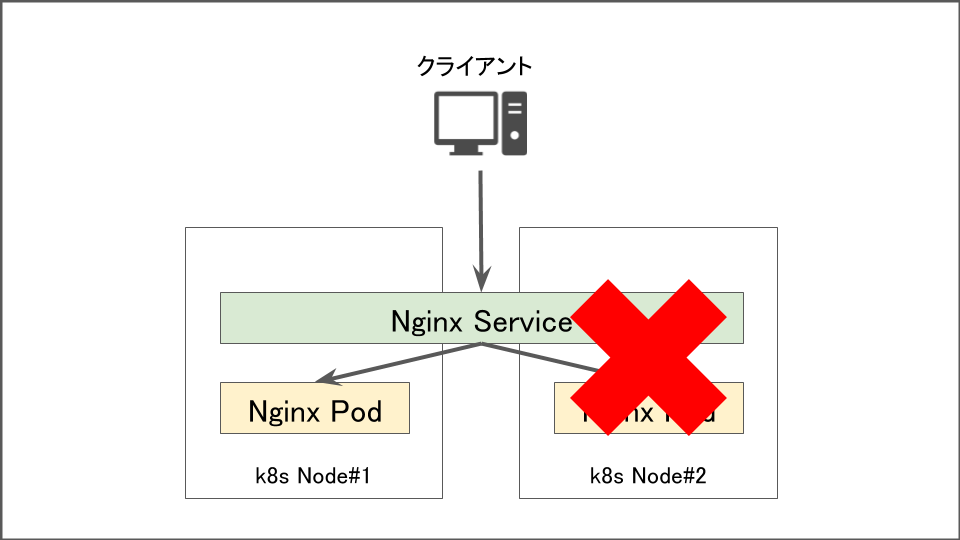
コンテナやPodを稼働させるDockerプロセスが停止したときは、該当ノード上で動作するPodへの通信が失敗します。その後–pod-eviction-timeout(デフォルト5分)の値にしたがって接続ができないPodが振り分け先から排除されます。
–pod-eviction-timeoutの値の間(デフォルトで5分間)はダウンしたコンテナにもリクエストが飛んでしまうため、podが2つ同時に起動している場合は通信成功率が50%となります。
※Pod数が増えた場合は(ノード数=Pod数ならば) 1 / ノード数 で算出できます
これを回避するには–pod-eviction-timeoutの値を変更するか、コンテナに対してReadiness Probeを設定するかです。
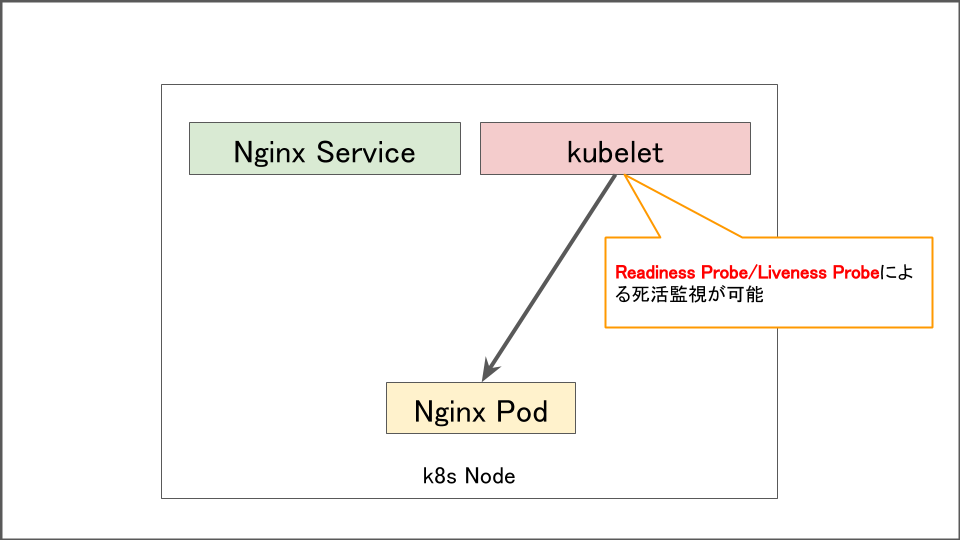
Readiness Probeを設定すると同一ノード上のkubeletから定期的に死活監視を行うことができ、Dockerプロセス停止時に迅速に停止したPodを検出しトラフィックの転送を中断することができます。
似た設定にliveness Probeもありますが、こちらはPodが正常に稼働しているかをチェックしPodを再起動する動作のため、そもそもDockerプロセスが停止しているときにはPodが再起動できないので効果がありません。
2021.05.25 追記
マネージドk8sでは–pod-eviction-timeoutを変えられない上、この設定はグローバルに変更を及ぼすため使いづらいケースがあります。そのときに使えるのがtoleration timeoutです。
k8sにはtolerationとtaintという仕組みがあり、PodとNodeの配置を調整することができます。Nodeへの接続が切れたときやnot-readyになった時などにNodeコントローラーが自動的にNodeにtaintを付与してくれるのですが、これをうまく利用するとNodeからPodを排除する仕組みを調整できます。
例えば以下のように特定のPodに対してNodeがunreachableまたはNot Readyの状態になった際は、2秒後にそのNodeからのEvictionを設定することができます。これによりNode障害検知〜Podの切り離しをスムーズに行うことができるわけです。
apiVersion: apps/v1 kind: Deployment metadata: name: busybox namespace: default spec: replicas: 2 selector: matchLabels: app: busybox template: metadata: labels: app: busybox spec: tolerations: - key: "node.kubernetes.io/unreachable" operator: "Exists" effect: "NoExecute" tolerationSeconds: 2 - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 2 containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
ちなみにこれをグローバルに設定したい場合は以下のような設定もありました。
--default-not-ready-toleration-seconds int Default: 300 Indicates the tolerationSeconds of the toleration for notReady:NoExecute that is added by default to every pod that does not already have such a toleration. --default-unreachable-toleration-seconds int Default: 300 Indicates the tolerationSeconds of the toleration for unreachable:NoExecute that is added by default to every pod that does not already have such a toleration.
Nodeが停止&kubeletプロセスが停止した時
MasterとNode間はkubeletプロセスが通信を行なっていますので、kubeletプロセスを停止したときはノードが停止している時と同じ挙動となります。
Dockerプロセスが停止した時と同じように–pod-eviction-timeout(デフォルト5分)の値にしたがって接続ができないPodが振り分け先から排除されます。
–pod-eviction-timeoutの値の間(デフォルトで5分間)はダウンしたPodにもリクエストが飛んでしまうためPodが2つ同時に起動している場合は通信成功率が50%となります。
※Pod数が増えた場合は(ノード数=Pod数ならば) 1 / ノード数 で算出できます
これを回避するには–pod-eviction-timeoutの値を変更したりNodeの数を増やすようにしましょう。
Dockerプロセス停止時と異なりこのケースの場合はReadiness Probeが効果を発揮しません。というのもReadiness Probeは該当のノード上のkubeletプロセスが死活監視を行なっているため、ノード停止時にはそもそも動かないからです。
調整方法
–pod-eviction-timeoutの変更方法
/etc/kubernetes/manifest/kube-controller-manager.yamlを修正します。
30sとすると30秒5m0sとすると5分30秒です
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
+ - –pod-eviction-timeout="30s"
〜
修正すると即時に反映されkube-controller-managerのPodが再起動されます。
参考
参考書籍